你的位置:凤凰彩票APP官方网站 > 六合彩 > 凤凰彩票 将 600 亿参数大模子装进手机的瓶颈, 终于被中国 AI 公司阻滞了
发布日期:2026-05-25 19:45 点击次数:147


一个 8B 参数的大模子,常常需要约 16GB 显存。参数越多,越吃显存,这便是为什么,内存价钱一天比一天高。
当今,有一种交替,不错省下 6 倍显存,却险些不损耗模子性能。
往日两年,围绕这个看似极点的念念路,一条世界性的时刻竞赛正在成型。而就在这条赛说念上,一个十足基于国产算力的决议,刚刚给出了我方的第一个回复。
模子被压到了不到 3B,同期,智商却不错保留 97%,以致更进一步,淌若勾搭 MoE 架构,畴昔不错径直在一部 8GB 内存的手机,运行 600 亿参数的大模子。
听上去匪夷所念念,怎么作念到的?
三个值,能跑大模子吗
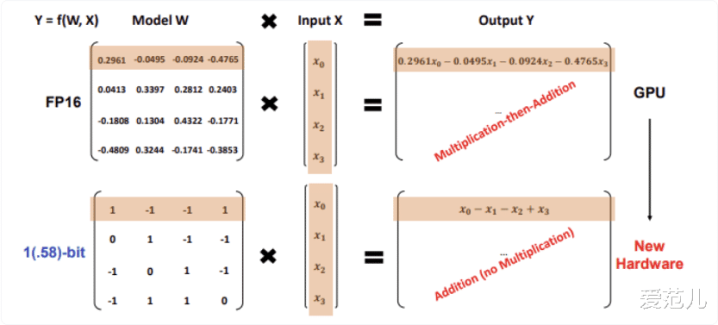
传统大模子用绝顶精准的数字存储,意味着每个权重不错取几万种不同的数值,精度很高,但也很占内存。三值量化是一个极点的反向操作:径直把可选的数值从几万种砍到三种。时刻上,这被称为 1.58-bit,因为编码三个值正好需要约 1.58 个二进制位。
这个压缩有多极点?打个譬如:淌若传统大模子的权重是一幅全彩相片,三值量化便是把它压成唯有黑、白、灰三色的极简图形。
直观上你会合计这势必失掉惨重。但往日两年的连续反复解说,模子权重里存在无数冗余信息。三个值,淌若分拨稳妥,足以承载绝大部分的模子智商。

这不是一个新见地。2024 年,微软连续院发布了 BitNet b1.58,第一次系统论证了三值大模子不错靠近全精度模子的性能。微软随后在客岁进一步发布了 BitNet b1.58 2B4T,一个 20 亿参数、4 万亿 token 考验的开源三值模子。上个月,好意思国公司 PrismML 发布了 Ternary Bonsai 系列,声称是首批营业可用的 1.58-bit 模子。
▲
上:Llama FP16架构,下:微软连续院开发的BitNet架构
学术界也相似在跟进:Tequila 提倡了治理三值量化中「死权重罗网」的新交替,TernaryLM 探索了从零开动的原生三值考验。
一条世界赛说念正在成型。但有一个关键问题长久莫得被回复:
三值大模子考验,能在国产算力上跑通吗?
昇腾上的第一次
这一次,在华为鲲鹏昇腾开发者大会(KADC 2026)上,面壁智能给出了谜底。
BitCPM-CANN 是面壁智能衔接清华大学、OpenBMB 开源社区发布的三值大模子系列。它的真谛不仅在于「又发了一个三值模子」。在世界赛说念上,BitCPM-CANN 作念到了三个此前莫得东说念主作念到的事情。
第一次,在华为昇腾上端到端完成三值大模子考验。此前统共公开的三值模子考验都在 NVIDIA GPU 上完成。国产芯片阵营第一次领有了我方的三值考验智商。 第一次,一次性把限制推到 8B。此前昇腾上的低比特考验停留在较小限制的考据阶段。BitCPM-CANN 径直发布了 0.5B、1B、3B、8B 四个档位,隐敝从手机到 PC 的完好意思端侧场景。 第一次,终显明与全精度模子的完好意思对照评测。11 项任务、四大类评测(知识、阅读泄漏、学科知识、数学推理),1B 到 8B 档位的智商保留率在 95.7%到 97.2%之间。
97.2%的智商保留率意味着什么?在 ARC、CMMLU、GSM8K 等主流评测中,BitCPM-CANN 三值模子与同尺寸 MiniCPM4 全精度模子的差距,如故小于很多全精度模子之间的差距。其中,3B 档位的保留率最高,达到 97.2%。
况且,这不仅仅论文里的数字,是能果然不错「拿来就用」的适度。BitCPM-CANN 的一说念尺寸版块如故开源,0.5B 到 8B 四个档位都不错径直下载复现。
关于练习面壁智能 MiniCPM 系列的开发者来说,BitCPM-CANN 便是 MiniCPM 眷属的三值版块,如故一套生态。在并吞个 GitHub 社区,眷属前辈聚集了 3 万颗星、Hugging Face 总下载量超 3000 万的「家产」,当今孕育出来了新的场地。
6 倍显存,从功绩器笔直机都「吃到红利」
比拟 BF16 全精度模子,BitCPM-CANN 省俭约 6 倍显存,这个数字开发者最能径直感知:一个 8B 参数的全精度模子需要约 16GB 显存,BitCPM-CANN 三值版块不到 3GB,不错流通运行在一部手机上,互助 MoE 与激活范围料理,60B 限制的模子有望装入末端勾引。
硬件端也如故准备好了。高通最新的旗舰芯片 8850 和 8397 支援 2-bit 原生推理,BitCPM-CANN 提供的正好是不错径直喂进去的低比特权重。
芯片厂商等供给,模子厂商等芯片,当今双方同期到位了,怎么不是一种「双向奔赴」。
江南体育(JNsports)官网app下载手机厂商对端侧大模子的参加一直在加快。上周 Google I/O 上,凤凰彩票Gemini Intelligence 全面经受 Android 勾引,从手机笔直表到车机;苹果也将在 6 月 WWDC 上展示下一代 Apple Intelligence 的要紧升级。

两大手机操作系统同期发力,共同指向一个实践:手机端侧要跑越来越强的 AI,内存便是最硬的瓶颈。谁能用更少的内存跑更强的模子,谁就掌捏了下一轮竞争的主动权。
骨子上,淌若勾搭通盘 AI 产业正在经验的阵痛,价值又会更进一竿:4 月时,高盛把全年 DRAM 价钱涨幅预期上调到 280%,好意思银预估世界 HBM 市集将达到 546 亿好意思元。

AI 基础门径最紧缺的资源便是内存,6 倍显存红利意味着不增多物理内存,就能把模子智商升迁数倍。在内存不时加价的情况下,这不是优化,是刚需。
三值量化不是「用精度换内存」的调解。当 97%的智商被保留住来时,证据传统 16 位模子里无数的精度可能是冗余的。三个值,足以承载一个大模子的绝大部分知识。低比特不再是工程上的省俭技巧,而是一种新的权重知识承载神志。
为什么是面壁智能,为什么是当今
当 AI 从云表走向末端,端侧模子正在成为个东说念主智能勾引的中枢智商。手机、电脑、车机,每一个贴近用户的末端都在等一个饱胀小、饱胀强、饱胀省内存的模子。这条赛说念的赢输手,不会是那些只会把模子作念大的团队,而是能把模子作念小、作念轻、作念到果然能跑起来的玩家。
为什么是面壁智能,能在端侧大模子这条路上,一直走在前沿?这个问题的谜底不在 BitCPM-CANN 自己,而在这家公司往日几年,一直在作念的一件看起来有些「不对群」的事。
面壁智能从开发之初就押注效力,在国内大多数团队追赶更大模子的时候,他们花了无数时刻作念底层考验框架 BM-Train,治理「怎么用更少的资源,训出饱胀好的模子」,这套基础门径聚集是自后一切的早先。
在 1.58-bit 方进取,面壁智能的判断早于行业共鸣。很多数团队还在游荡极低比特是否可行时,面壁智能就采取了这条道路,先在 GPU 上跑通了完好意思的考验进程和交替论,再合座迁徙到昇腾平台上。不错说,BitCPM-CANN 不是把一个模子移植到了国产芯片上,而是把一整套经过考据的考验交替、效力道路和工程体系,搬进了国产算力的底座。
在模子层面,面壁智能的端侧模子 MiniCPM 系列在 GitHub 上聚集了进步 3 万颗星,Hugging Face 开源总下载量进步 3000 万,是端侧大模子规模最受接待的中国开源模子眷属。
BitCPM-CANN 恰是 MiniCPM 眷属向三值量化的蔓延,远不啻一个展示性的「PPT 模子」,是一个果然可复用的工程地基。它背后的考验链路如故被千里淀为昇腾低比特考验的基础门径,后续统共想在昇腾上作念低比特考验的团队,都不错在并吞套底座上起步。
值得一提的是,BitCPM-CANN 还在华为昇腾上完成了端到端的三值考验,考验效力达到老例基线的 95%。这解说了这套交替论不依赖特定硬件平台,国产算力相似不错跑通。

不是等硬件变得饱胀宏大来符合模子,要让模子变得饱胀机灵来符合硬件。
从考验端的华为昇腾,到推理端的末端芯片,再到开源的模子和考验剧本,这是一条完好意思的国产闭环,框架国产,芯片国产,模子国产,交替论自主。面壁智能的下一步如故明确:进一步升迁模子的智商保留率,用 MoE 架构膨胀更大限制模子的容量,把 6 倍显存红利完好意思开释到部署中。更永远的想法,是隐敝从预考验到对都的全进程低比特化。
从底层考验框架 BM-Train,到端侧模子眷属 MiniCPM,再到 BitCPM-CANN,面壁智能用几年时刻搭建了一套完好意思的端侧大模子时刻体系。在世界赛说念上,濒临微软、PrismML,面壁智能展现出了私有的不同上风之处在于:从框架、交替论、模子到芯片适配,构建了一条完好意思的端侧时刻道路。
当 AI 竞争从「谁的模子更大」转向「谁能让智能果然跑在每一台勾引上」时凤凰彩票,掌捏端侧时刻言语权的东说念主,才站在了最有意的位置。
 备案号:
备案号: