你的位置:凤凰彩票APP官方网站 > 分分彩 > 中国官方网站 蓄意一款针对VLA/扩散兼顾天下模子的芯片
发布日期:2026-05-16 02:44 点击次数:94

当今不管是具身智能照旧自动驾驶,时期蹊径齐已大幅束缚,基本上即是两条时期蹊径,一条是VLA蹊径,用在自动驾驶领域或是VLA+传统蹊径的夹杂架构。另一条即是WA蹊径,即天下模子+Action Expert。再有即是大齐用天下模子增强VLA鲁棒性的架构,本色上照旧VLA蹊径。不管哪条蹊径齐离不开扩散模子。
博世的DiffVLA架构
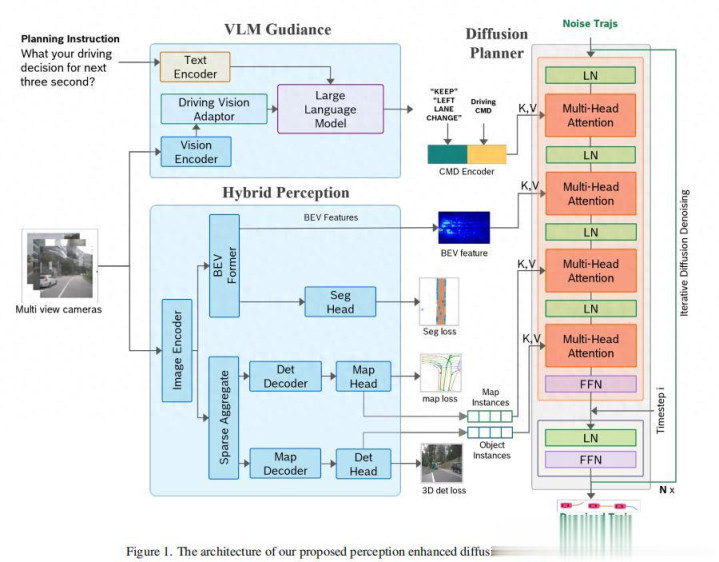
博世的DiffVLA架构,概况率用在奇瑞星途星纪元ES上,屡次在智驾大赛赢得第又名的好收货,这是典型的面向量产的VLA,其中感知图像和点云矢量化抽取特征后干涉VLM和传统感知算法,会通明干涉扩散模子的Action Expert输出轨迹。
DiT架构
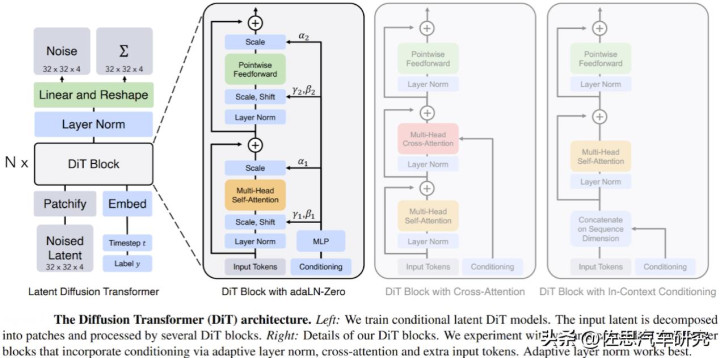
天下模子的中枢是DiT架构,见上图。DiT最中枢、最无可替代的上风,在于其Transformer架构对时序信息(Temporal Information)的自然亲和力。这使得它不单是是一个更好的图像生成器,更是一个为视频、动画乃至更复杂的序列生成任务量身打造的“天选之子”。与早期的扩散模子径直在像素空间上操作不同,DiT沿用了Latent Diffusion Model (LDM) 的高效政策,其所有中枢操作齐在一个经过VAE(变分自编码器)压缩后的低维潜空间(Latent Space)中进行。这极地面裁汰了辩论复杂度,使得模子不错专注于学习数据更高眉目的语义结构,而非像素级的冗余细节。
AdaLN-Zero(Adaptive Layer Normalization with Zero Initialization)是 Diffusion Transformer (DiT) 架构中的枢纽模块,主要用于将扩散过程中的条款信息(如时期步、类别标签)高效地融入 Transformer 块中。其核姿色念是通过一个 MLP(多层感知机)将标量时期步映射为向量,进而生成用于缩放(scale)、平移(shift)和门控(gate)归一化特征的参数。
过程大致分为两步,第一步是标量输入 (Scalar Input),开动信息:扩散过程的时期步(如第 500 步)和类别标签往往是标量。经过 Sinusoidal Position Embedding(正弦位置编码)或径直镶嵌,迁徙为高维的荫藏向量(Embedding Vector)。向量化时期步:在视频生成模子(如 Wan)中,为了顺应不同帧的条款,标量时期步可能会被膨胀为基于批量大小和帧数的向量。第二步是向量输出 (Vector Output - 调制参数),AdaLN-Zero 通过一个线性层(MLP)将条款向量迁徙为 6 个特征映射参数,这些参数是向量形势。
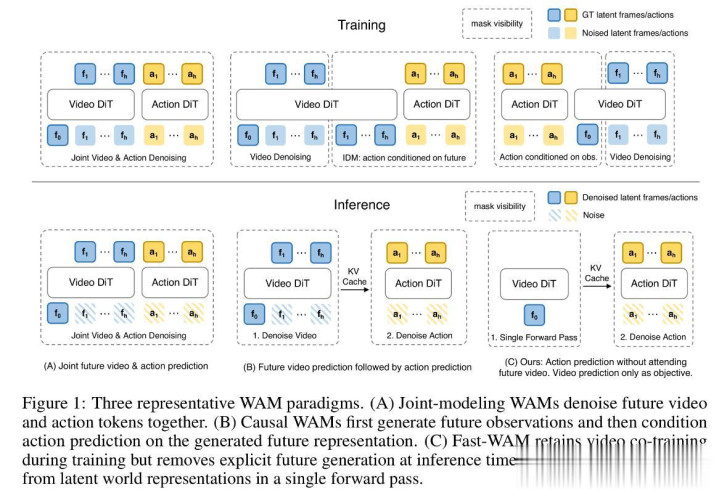
现存 WAM(天下算作模子即天下模子加算作众人) 归纳为三类范式:吞并建模、先遐想后扩充,以及 Fast-WAM 的“检会时建模、推理时直迁徙作”。不管哪一种DiT齐是中枢,不管具身智能照旧自动驾驶齐是如斯。而Action Expert大多是隧谈扩散模子或流匹配模子,不管哪一种,中枢照旧DiT架构。
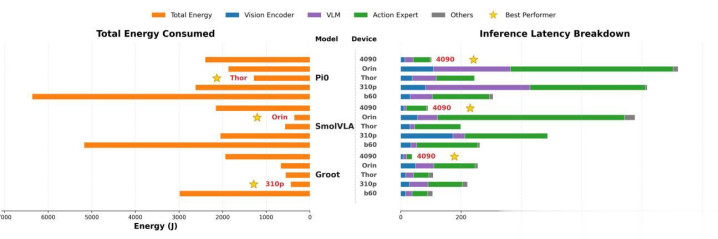
典型的具身智能VLA由视频编码器、VLM和算作众人组成,上图分析了三个具身智能VLA模子在不同处理器上的蔓延,其中4090是英伟达的RTX 4090,B60是英特尔的显卡,与其配备的CPU是英特尔11代i7-11700,310p是华为的昇腾310p,2023年推出的RTX4090具备压倒性的完全上风,施行上RTX4090不错碾压当今99%的端侧推理用芯片。第二名是英伟达的Thor-X,不外与第三名英特尔B60之间差距很小,在GR00T上险些没辞别,华为310P第四,Orin最差垫底,自然标称170TOPS,但施行上其DLA部分无法用于transformer架构,施行8位精度广宽算力只好约83.5TOPS,远不如华为310P。
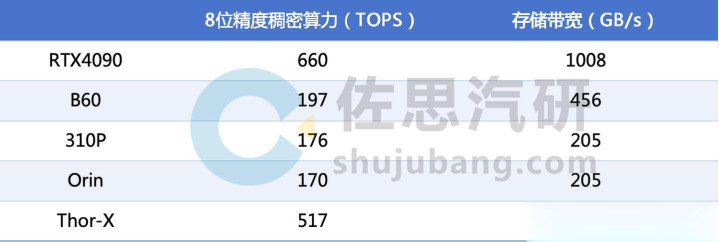
整理:佐念念汽研
SmolVLA是一个很小的具身智能VLA模子,总参数约莫4.5亿,流匹配的Action Expert只是占了1亿参数,但在辩论过程中占据了特出60-70%的推理时期。主要原因是当今的GPU或NPU所以矩阵运算为主,不适当DiT。
DiT的采样阶段采样过程可占据总推理蔓延的70%,主要瓶颈在于词表级logits的大规模内存读写、基于归约的token聘请,以及迭代掩码更新。logits张量的结构,其规模为[B × L × V],其中B为批量大小,L为块长度,V为词汇大小(在起首进的模子中往往为120k-160k)。即使是罢休的建树,每步也会生成多兆字节的张量,时时特出片上内存容量,自然量化不错减少内存占用,但并未惩办限度密集型、以归约(reduction unit)为主的采样使命负载。Top-K/Top-P聘请:对每个位置的V维logits进行归约操作,选出候选token,Top-K聘请、掩码索引波及非连续内存探问,这是一种非轨则的存储探问形式。DiT往往需要屡次迭代(往往5-20步)直到所有位置束缚。
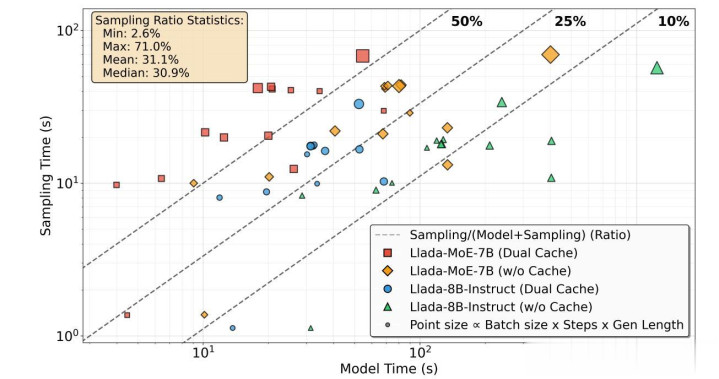
矩阵运算为主的GPU和NPU,主要方针即是TOPS数值,这个在DiT架构上毫无价值,要对应DiT架构,中国官方网站主淌若要加多标量和向量算力,向量算力至少要有6TFLOPS。提高内存与向量标量辩论单位的耦合进度,提高片上SRAM的容量,提高存储带宽。
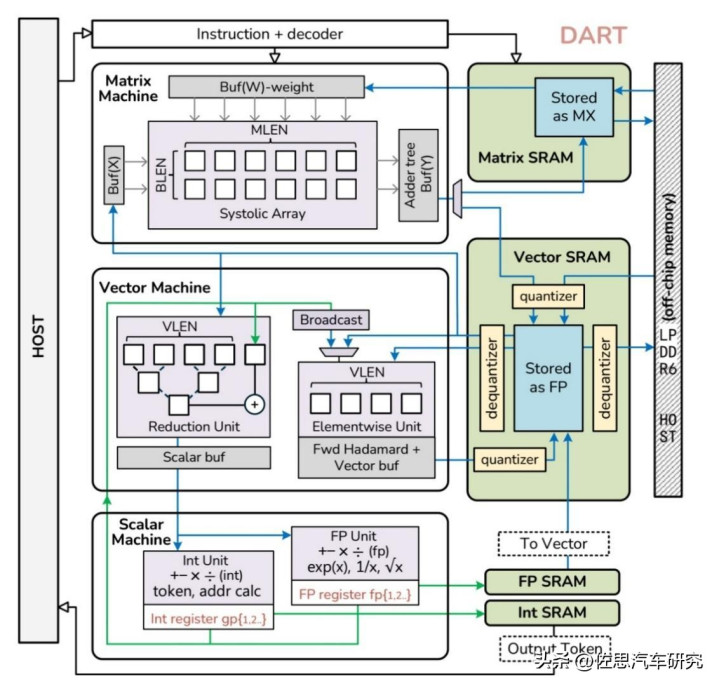
针对扩散和天下模子的芯片架构(上图),基于论文NPU Design for Diffusion Language Model Inference,略作修改,将奋斗的HBM内存换成相对相比低价的LPDDR6,这款芯片也能针对AI Agentic。每个辩论单位,包括矩阵(张量)、向量(矢量)和标量齐通过DMA配备一些紧耦合SRAM,SRAM容量有限,和本钱正比,因此应该尽量向标量和向量单位歪斜,向量使用权重压缩与解压缩,提高SRAM使用效果,标量则将浮点和整数值分开存储,也为提高SRAM使用效果。
LPDDR6 这一次在内存带宽的增幅上赢得了史诗级教化。为何说是史诗级呢?因为不同于以往 LPDDR 的 Gen2Gen 增益只是只是将内存速度教化,LPDDR6 此次同期加多了内存速度和内存位宽。LPDDR6 的原始通谈宽度从 16bit 教化到了 24bit,对应的手机端/PC 端所主流建树的双通谈 LPDDR 位宽也就自然则然的成了96bit 和192bit。而LPDDR6之前的双通谈是64bit和128bit,要窄得多。
典型的LPDDR6系统其存储带宽是96*4/8*14.4=691GB/s,高性能不错提高到96*6/8*12.8=1037GB/s,还是不错放肆碾压特斯拉AI5的819GB/s,而况本钱可能比特斯拉还要低。那为什么特斯拉没用LPDDR6,很浮浅,AI5的蓄意时期是2023年底或2024岁首,2025年中期LPDDR6圭臬才公布,同期才有厂家出售LPDDR6物理层IP,当今LPDDR6的物理层IP主要由三家提供,鉴识是EDA大厂新念念科技,Cadence和国内的芯动科技,一般齐是基于2纳米或3纳米的。
关于初创厂家,RISC-V是最好聘请,因为这么在蓄意编译器时不错自主掌控,天真性很高,当今标量和向量往往齐情投意合,基本上齐选择超标量SIMD蓄意,RVV是RISC-V圭臬辅导集的一个膨胀, 宗旨是为RISC-V架构提供vector处贤达商,RVV一共32个寄存器, 每个寄存器的长度为VLEN (bit), VLEN是硬件厂商竣事的固定长度, 需淌若2的幂次方, 最小为64或128. 比喻说VLEN=512就相配于Intel的AVX512辅导。

CPU的IP不错聘请中国台湾晶心Andes的向量系列,兼顾标量与向量,瑞萨曾选择过晶心的AX45MP。也不错聘请SiFive的X280或X390,性能上晶心要比SiFive强少许,X390的DMIPS是3.3/MHz,CoreMark是5.7/MHz。SiFive维持RVA23,也维持低精度的FP4,天真性和生态略好于晶心,祈望汽车就聘请了SiFive的X280。中枢数目至少是4个,6-8个更好。
Host(主机)的CPU自然也需要很强,因为有大齐迁徙编排和译码的使命,齐需要CPU真贵,而况汽车领域,并发运用许多,畸形是舱驾一体,CPU单线程运算智商不错裁汰要求,多线程要高,也即是中枢数目要多,至少18个CPU内核,CPU架构最低亦然Cortex-A78AE,本钱不太明锐可选Neoverse V3AE或Adonis Neoverse V4。
开云app登录入口提高存储带宽,加强标量和向量运算智商,至于矩阵乘法的算力不错稳妥缩减规模,因为早已不是经典Transformer把握的期间,DiT将在相配万古期内是主流,只贵重矩阵乘法,动辄上千TOPS的芯片弘扬会很倒霉。
免责讲明:本文不雅点和数据仅供参考中国官方网站,和施行情况可能存在偏差。本文不组成投资苛刻,文中所有不雅点、数据仅代表笔者态度,不具有任何素养、投资和方案成见。
 备案号:
备案号: